8일차 수집해온 데이터를 집계와 시각화하는 데 도움이 되는 함수를 여럿 알게 됐다.
차근차근 나열해보자


먼저 불러온 데이터의 원형태이다.
이 중 속성 이름을 가지고 원하는 데이터만을 추출할 수 있다.
우선 속성이름을 기준으로 추출할 때는 filter함수를 이용해야 한다.

위 filter함수의 괄호 속 regex는 정규 표현식을 뜻하며 내가 원하는 속성이 "age"라면 그 자체를 기입하여 "age"만 특정 하여 추출 가능하다.
또한 원하는 글자열이 포함된 속성들만 필터링 이 가능하며 표현 형식은 이러하다.


위 속성 중 e로 마쳐지는 'age'와'exercise'를 문자열 끝으로 하여금 추출한 기능이다.
만약 성적관련 데이터를 받았을 떄 'SCORE$'를 regex에 기입한다면 점수만 보여지도록 필터링이 될것이다.

위는 데이터 중 숫자로만 이루어진 데이터들의 속성들만 고른 함수 표현이다.
당연히 문자 데이터만 출력도 가능하다. 이건 필터링하는 작업이 아닌 데이터타입으로 구별을 하기에 select_dtype을 잊지말자.

#######
조건 설정으로 데이터를 출력할수있다.

먼저 bool타입 true / false 값의 식을 만들어진다.
위처럼 'age' 행의 데이터들 중 30 이하 값들은 모두 TRUE값을 가지게 된다.
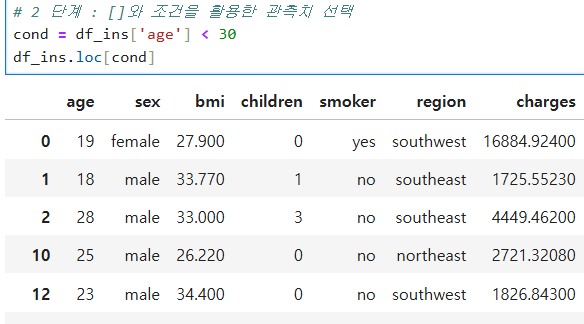
그후 변수에 넣어서 loc 함수로 응용하면 30이하 나이의 데이터들만 출력하게 된다.
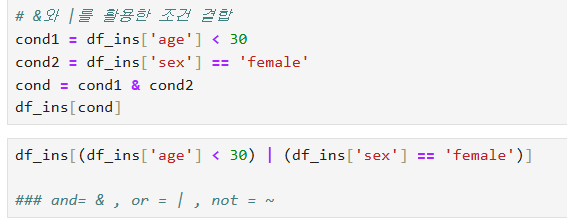
두 조건을 만들고 & 을 이용하여 결합하는 형태도 있으며
좀더 길게 중괄호 안에 두 조건문을 넣는 형태도 존재한다.

위 함수는 숫자열 변수인 속성 'math score' 에서 80~90사이 값을 포함한 데이터를 출력하는 함수이다.
inclusive=방향은 , 를 기준으로 포함하는 수를 표시한다 생각하자.


위 함수들은 상위 관측치 하위 관측치를 출력하는 함수이며, 앞쪽 n은 표시할 갯수를 의미한다.

위는 중복값들을 없애고 출력하는 함수이며 생략할 중복값은 뒤차례값들을 가려준다,


위 함수는 데이터 정렬을 돕는 함수이며 유의점은 오름차순의 함수가 있지만 내림차순의 함수는 없어 ascending 으로 내림차순을 지정해줘야한다.

이제 수치형 관측 들을 집계하는 함수를 알아보자
먼저 평균, 합계, 분산 및 표준편차, 중간값, 관측치 수 등을 집계 가능하다.

새로운 라이브러리 seaborn 은 시각화에 있어서 효과적인 라이브러리로 알아두면 용이하다.

seaborn 라이브러리 로 표현한 히스토그램 식이다. 등간격과 막대의 분간 경계선이 표현돼 가독성이 매우 좋다.

4분위수로 표현한 수치 데이터

위는 박스플랏이며 유의할 점은 , 뒤쪽 x 와 y=으로 표현할 축을 지정할 수있다.