인공지능 트랜스포머

오늘의 강의 시작 부분은 NLP의 정의 부터 맞이한다.
NLP란 Natural Language Processing의 약자로 자연어 처리를 의미한다.
가령 이 기술이 우리 인간을 인공지능과 대화를 가능케할 수단을 의미하는 데
교수님이 제공하신 강의집에서도 엔비디아 ceo인 젠슨황의 모습을 한 아바타와 인터뷰자들간의 대화를 진행하는 영상을 엿볼 수 있었다.

마치 이부분에서는 사람처럼 인공지능도 언어를 학습함을 엿볼수 있었는 데
우선 언어의 이해와 언어의 생성이라 두 부분이 크게 와닿았다.
인공지능 또한 언어의 정보습득면에서 당연히 제로베이스에서 시작했을 테고, 천천히 데이터를 쌓아 올랐을 것이다.
그러면서 인간처럼 지식 정보의 습득이 쌓일 수록 양질의 정보를 형성한다는 것인데

아래 차트를 보면 데이터 세트 크기의 점차 증가함에 떄라 정확도 역시 정비례하게 상승함을 알 수있다.
하지만 현재 우리가 애용하고 있는 gpt의 수준은 냉철하게 고등학교 수준이라고 하셨다.
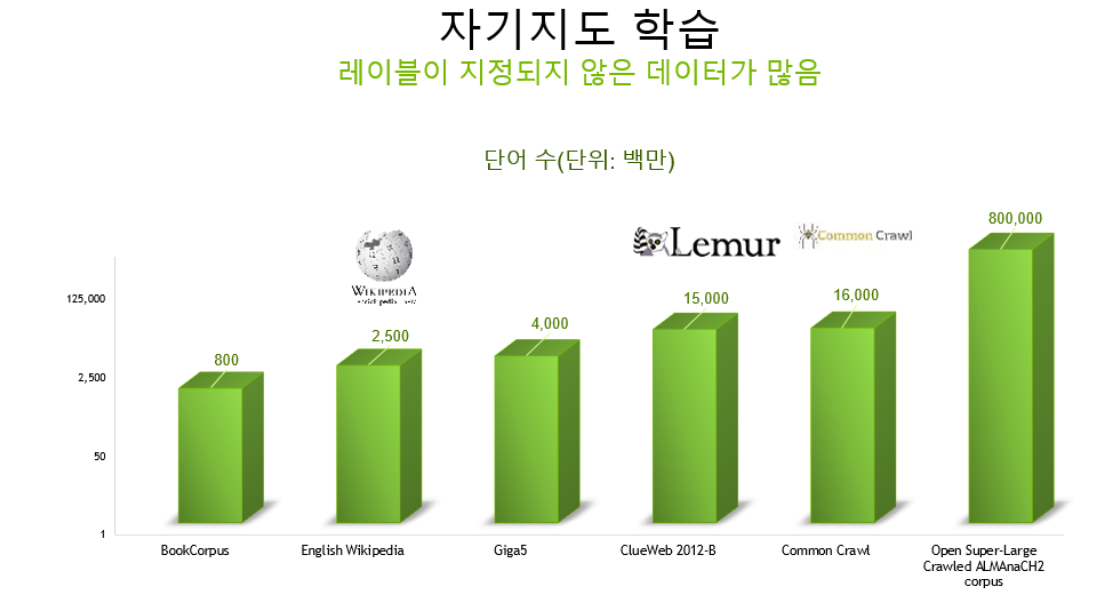
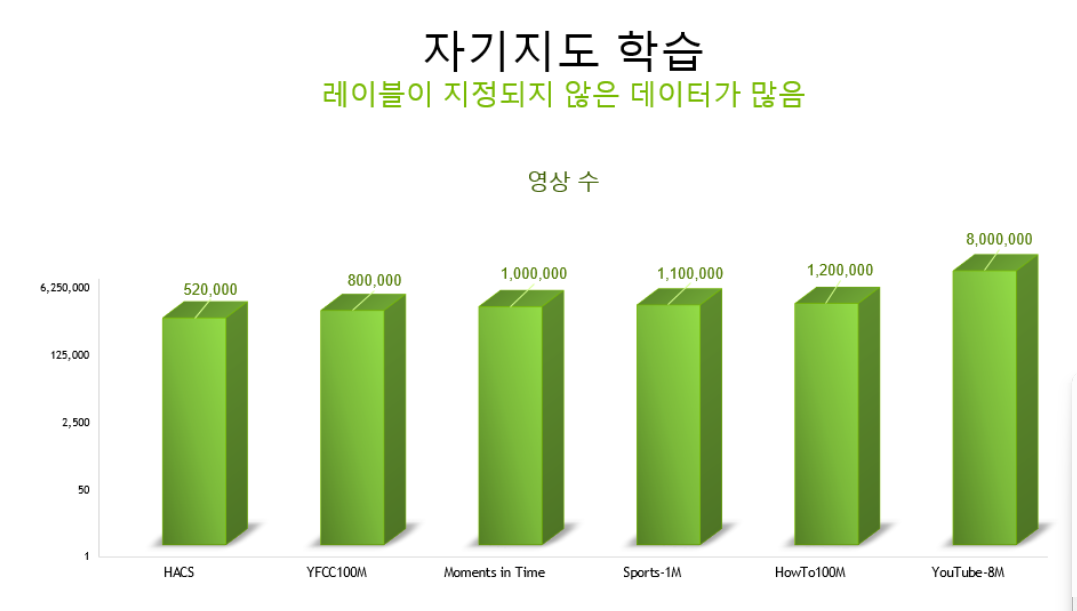
위 자료들이 아직 지도 학습이 되지 않은 정보들이며 무엇보다 현 수준이 고등학생에 불과하다는 점이 매우 놀라웠다.
앞으로의 발전성이 더욱 기대되는 가운데
교수님은 OPENAI 가 아닌 LLM모델 오픈소스 기반인 메타의 라마를 소개해주셨다.
라마는 오픈소스를 기반으로 작동하여 여러 커뮤니티를 중심으로 지식의 축적을 쌓는 LLM모델 이고,
이는 프로그램 언어에 있어서 파이썬이 주력 언어로 자리매김 할 수 있었던 절차를 똑같이 밟을 거라 생각한다.
파이썬 또한 오픈소스로 통해 수많은 유저들의 라이브러리를 쉽게 공유하고 수정 가능하여 범용성이 커졌듯이
인공지능 또한 집단 지성의 규모의 힘을 무시 못할거라는 생각을 가지고 됐다.