인공지능 학습 모델

파이썬 pandas에서 제공하는 인디언들의 당뇨질환 관련된 데이터 셋이다.

우선 이런 데이터를 받게 되면 히트맵을 작성 해보자
그럼 상관관계가 있는 변수들을 쉽게 집을 수 있을 것이다.
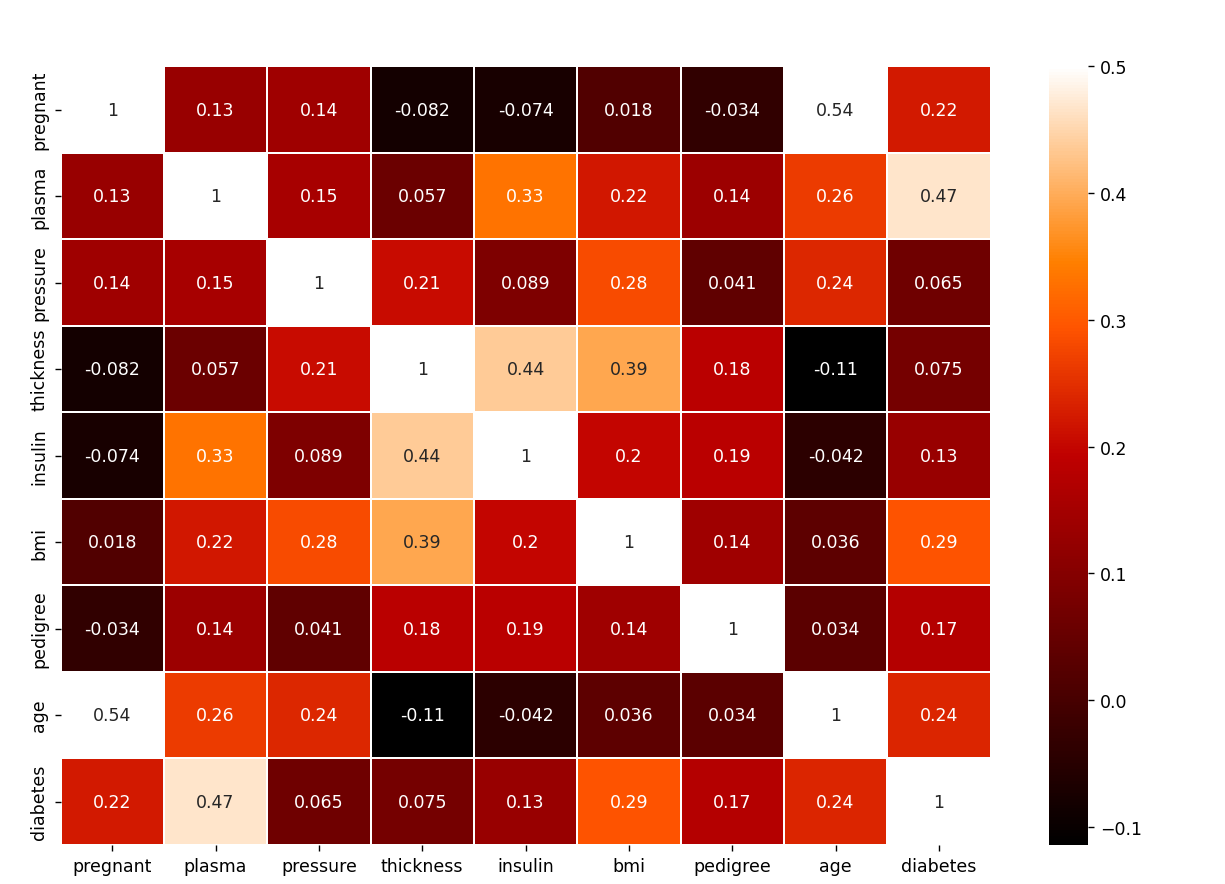
아래가 위 데이터셋의 히트맵이다. 각 변수의 상관관계를 색깔의 짙음으로 표현해주는 데 1에 가까울수록 상관관계가 높음을 의미한다. 예시로 당뇨와 임신의 상관관계는 0.22이고 당뇨와 나이는 0.24의 상관관계를 보여준다. 이를 토대로 해석하면 임신의 여부보다는 나이가 좀더 당뇨와 밀접한 관계를 알 수 있다.

위에서 불러온 데이터셋은 수기로 작성한 숫자를 데이터이다.

0~9까지의 숫자를 여러 수기 형태로 작성됐는 데 이를 픽셀값으로 하여금 표시를 했다. 흑백이미지 이므로 색이 부분을 값을 넣어줘 나름의 숫자의 형태를 갖춘 데이터로 표시한 것이다.

이제 이부분을 학습 데이터와 훈련데이터를 나눠주는데 255로 나눠 주는 이유는
색의 짙음을 255까지 수로 표현했기에 정규화를 위해서 0과1사이 값으로 바꿔준 것이다.
그렇게 정규화 작업을 거쳐줘야 후에 있을 학습에 있어서 좀 더 효율적으로 움직일 수 있기 때문에 값의 폭이 넓을 때는 정규화 작업을 꼭 거치는 것을 명심하자.
뉴런의 수는 64, 32,16의 각 레이어층에 할당해주고 activation 은 relu로 진행 해준다.
그리고 마지막 출력층은 0~9 총 10가지의 수로 종류하기에

아래에 맞춰 뉴런의 출력층을 10개로 설정해준다.


보면 accuracy가 90퍼 이상으로 진행됨을 볼 수 있다. 학습률이 꽤나 좋음을 알 수있고 수기 이미지 학습 알고리즘이 잘 형성된 것을 의미한다.