인공지능 3일차
바로 예제 코드 부터 들어간다.

IRIS 라이브러리에서 데이터셋를 가져와 예제코드를 진행해 본 것이다

가져온 데이터의 개수는 150개이다
그중 8:2비율로 훈련데이터와 테스트 데이터로 나눠준것이다
120개 데이터가 학습을 진행할 훈련데이터이고
30개 데이터가 테스트를 해볼 데이터셋이다.

선형회귀를 적용하여 예측분석으르 진행할 테고
방금 나눈 훈련 데이터를 FIT함수를 이용하여 머신러닝을 적용시킬 것이다.
여기서 FRINT weight 와 bias는 기울기와 y절편으로 보면 될듯하다.
regression.score 는 훈련데이터로 맞춰본 점수를 퍼센티지해서 보여준다.

120개의 훈련데이터 중 92퍼선트로 맞췄다.
꽤 좋은 정확도를 보여주기에 한번 테스트 데이터로 검증해볼것이다.
독립변수 훈련데이터를 기반으로 예측해보는 예측값 변수를 만들어준다.
형태가 소수점까지 표현되기에 반올림 형식 코드를 이용하여 정수 형태로 만들어 준다.

이것이 테스트 데이터로 만들어본 예측 변수와 실제 값의 출력이다.
꽤 좋은 정확도를 보여준다.

위 역시 당뇨병 환자 데이터를 이용하여 머신러닝 적용한 예측 모델이다
큰틀에 있어서 전과 크게 다른 점이 없는 데 어째서 훈련 데이터와 테스트 데이터를 8대2로 나눈 것일까

이런 문제들이 발생하기에 적절한 비율로 머신러닝을 굴리게 되는 것이다.

개 품종을 예측 해보기 위한 데이터셋을 직접 만들어 본것이다.
품종은 닥스훈트와 사모예드 두 품종으로 정했으며
길이와 높이 변수를 가지고 예측을 해볼 예정이다.
먼저 각 닥스훈트와 사모예드의 길이와 높이 산포도 차트를 보자
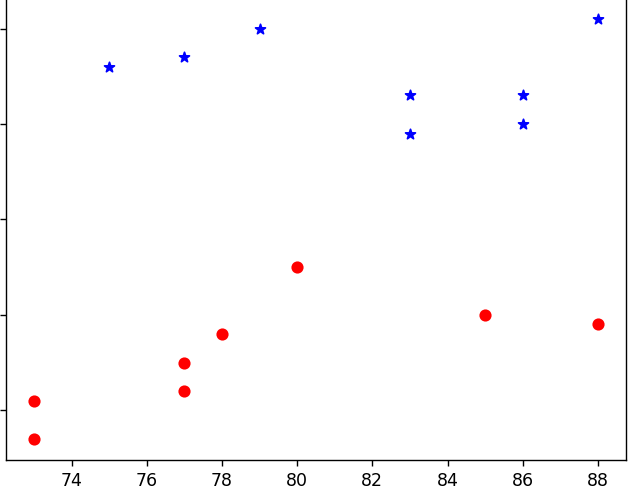
별모양이 사모예드 동그라미 모양이 닥스훈트 이다.
길이와 높이와 분포도 차이에서 확연한 차이가 보여지긴 한다.

위는 닥스훈트의 높이와 길이의 데이터를 합해서 닥스훈트 데이터셋을 만들어 줬고 이 기반으로 닥스훈트의 결과값이 나오면 0이라는 출력문이 나오게끔 정한 것이다.

군집을 5개의로 하여 근접한 변수들로 하여금 판별하게 하는 k군집 분석이며
개 품종을 맞춰보는 예측 모델을 만들어 본 것이다.