금일부터 데이터 분석강의에 들어감에 있어서
강사님도 바뀌게 됐다. abc부트캠프 데이터 분석을 책임져주실 오소진 교수님
이 교수님은 한밭대학교에서 교수로 재직하고 계시며 이번에 크롤링에 관하여 교육을 진행해주시기로 하셨다.
오전에는 5장의 교안을 통해 빠르게 중요 부분만 체크해주면서 진도를 나가주셨다.
처음 접하는 html의 시스템이라 이해가 쉽지는 않았지만 실습을 통해 서서히 알게 될거라 생각하며 빠른 진도에 발 맞춰
5장의 교안 속강을 마쳤다.
점심식사 후 실습
실습주제는 네이버 뉴스에서 랭킹 뉴스에 관한 데이터 분석이였다.
네이버 랭킹 뉴스는 가장많이본 뉴스와 /댓글이 많이본 뉴스가 언론사별로 랭킹순위가 매겨 있다.
우리는 이 웹사이트를 크롤리하여 데이터를 추출한 후 분석을 실습을 진행하는 것이다.

가장 먼저 분석 툴들을 다운로드해주고

분석 라이브러리들을 준비해준다.

그런 다음 데이터 프레임을 만들어 추출한 데이터들을 위 형태로 정리할 생각이다.

위는 랭킹박스의 div만 추출하는 것이다.

위 형태처럼 여러가지 언론사별 랭킹 있을 때 위 코드는 언론사별 리스트 전체 추출하는 것이다.
위 작업하고 print를 해보면 게재된 리스트묶음들이 보일것이다.

위 작업은 언론사 리스트에서 언론사명만 추출하는 것이다.
이또한 프린트 하면 게재된 언론사명들이 모두 보이게 된다.

위는 리스트묶음에 속한 여러 기사들을 읽게 하는 과정이다.
위 사진을 빗대어 표현하면 중앙일보의 5가지 랭킹뉴스를 읽어주고 연합뉴스의 랭킹뉴스 등 이런식으로 모든 리스트 묶임에 속한 뉴스들을 모두 추출하는작업이다.

위 작업은 이제 부속 설명 정보들을 읽어오는 작업이다, 기사 제목, 주소, 순위등을 읽어오고 데이터 프레임에 맞게 조정해주면 다음과 같이 data프레임들이 만들어진다.


이제 이 데이터 프레임을 시각화하는 작업을 거쳐보면
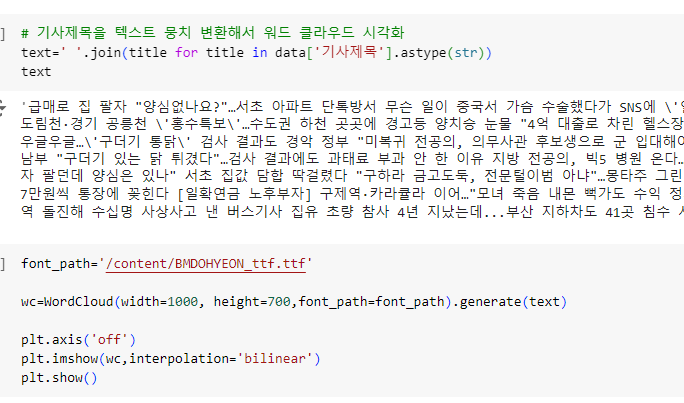

이러한 워드 클라우드를 볼 수 있게된다.
첫 수업부터 매우 실무적인 작업을 배우게 돼 정말 시간이 가는 줄 몰랐고 솔직히 온전히 습득하진 못했다.
그래서 이후 진행된 프로젝트에 향해서 전혀 갈피를 못잡게 됐기에 정말 공부와 복습이 매우 절실히 느껴지는 생각이 든다.
그렇게 집으로 복귀 하여 프로젝트에 관해 복습을 하며 나름 공부를 해본 결과

해당 코드문을 작성해봤다. 하지만 주어진 프로젝트의 수행을 완벽히 수행하지 못하여 몇가지 손을 봐야하고 그 수정할 부분을 선별하기 위해 코드문 하나하나 다시 의미를 되 짚어보며 수정문을 찾아야 하는 과정을 밟아야 하는 이 좀 처럼 쉽지 않다고 느껴지지만 이 작업을 수행한다면 꽤 큰 성취를 얻을 거라 짐작한다.